2014-03-28 18:11:32
设有两类文件, 扩展名分别为A和B, 可能的集合关系如下:
-
并集 $A \cup B$: 属于A或B的文件, 所有可能文件
ls \*.A \*.B | sort | uniq -
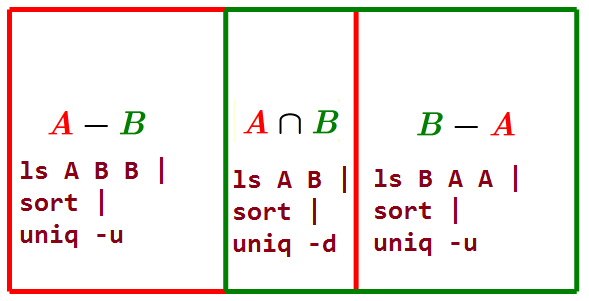
交集 $A\cap B$: 同时属于A和B的文件, A和B互有对应的文件
ls \*.A \*.B | sort | uniq -d -
交集的补集 $\overline{A \cap B}$: 不同时属于A和B的文件, A和B无对应的文件
ls \*.A \*.B | sort | uniq -u -
A的差集 $A-B=A \cap \overline{A \cap B}$: 属于A但不属于B的文件
ls \*.A \*.B \*.B | sort | uniq -u -
B的差集 $B-A=B \cap \overline{A \cap B}$: 属于B但不属于A的文件
ls \*.B \*.A \*.A | sort | uniq -u
若A包含B, 上面的做法可以简化.
-
并集 $A \cup B=A$:
ls \*.A -
交集 $A\cap B=B$:
ls \*.B -
交集的补集 $\overline{A \cap B}=A-B$:
ls \*.A \*.B | sort | uniq -u -
A的差集 $A-B=A \cap \overline{A \cap B}$:
ls \*.A \*.B | sort | uniq -u -
B的差集 $B-A=B \cap \overline{A \cap B}=\emptyset$
应用场景
提交很多作业, 每个作业有一个输入文件, 完成后会产生一个输出文件, 输入文件和输出文件存放于同一文件夹下 适当利用这些命令可以快速过滤文件, 知道哪些作业已完成, 哪些作业未完成, 也可以快速地将已完成的作业移到其他地方保存.
