- 原文 More bang for your buck: Improved use of GPU nodes for GROMACS 2018, DOI: 10.1002/jcc.26011
- 2019-08-28 16:47:25 翻译: 刘玉杰; 校对: 李继存
摘要
我们确定了在Linux计算集群上, GROMACS 2018程序运行分子动力学(MD)模拟的最佳硬件. 因此, 我们在各种计算节点上对GROMACS性能进行了基准测试, 并将其与节点成本联系起来, 其中的成本可能也包括能源和冷却成本. 与我们早先使用GROMACS 4.6在2014年的硬件上进行的调查一致, 消费级GPU节点的性价比远高于CPU节点. 然而, 在GROMACS 2018中, CPU到GPU处理能力的最佳平衡更多地转向了GPU. 因此, 与针对旧GROMACS版本优化的节点相比, 针对GROMACS 2018及更高版本进行优化的节点具有更高的性价比. 而且, 向GPU处理的转移使得使用新GPU升级旧节点变得更便宜, 得到的性能与相近的全新硬件基本相同.
引言
分子动力学(MD)模拟是一种成熟的计算工具, 用于从物理学的角度, 在原子水平上研究和理解生物分子的功能. 一个溶剂化分子的模拟系统可以由数千到数百万个原子组成, 具体取决于它是一个小的蛋白质还是像核糖体[1]或病毒外壳[2]这样大的复合物. 为了在生物相关的时间尺度上得出原子运动的时间演化, 需要计算数百万个时间步. 为了得到具有统计学意义的结果, 此过程通常要在不同起始条件下重复多次. 因此, 研究单个生物分子系统就很容易占用多个现代计算节点, 运行数周, 而一个进行MD计算的典型研究小组的所有模拟项目需要一个中型计算集群不间断地运行.
无论所需的集群硬件是由使用它的部门购买, 还是使用高性能计算(HPC)中心的服务, 最终必须有人决定购买什么. 这个决定并不简单, 因为可用的硬件是多种多样的. 节点具体应该如何? 节点是应该拥有多个弱计算核心, 还是拥有较少的强计算核心? 多套节点是否比单套节点更好? 每个GPU需要多少个CPU核心? 哪种GPU类型是最佳的? 内存与节点间的连接呢?
专为不同软件应用设计的全方位集群节点通常包含高端CPU, 具有双精度浮点性能很高的GPU, 大的内存和昂贵的互连. 同时满足这些需求的结果是每个应用程序的计算性能与节点价格的比值非常低. 我们的方法完全相反: 通过具体化来实现成本效益的最大化. 我们只关心一种特定的应用, 即MD, 并寻找在固定预算下能够获得最高模拟吞吐量的硬件, 这是通过在硬件的使用寿命内能够产生的轨迹的总长度来衡量的.
可用于生物分子模拟的MD代码有很多, 其中包括ACEMD[3], Amber[4], CHARMM[5], Desmond[6], LAMMPS[7], NAMD[8], OpenMM[9]和GROMACS[10]. 我们使用GROMACS, 因为它是最快的MD引擎之一, 使用广泛且免费.
我们的基本问题是: 在预算固定的情况下, 我们如何才能产生尽可能多的MD轨迹? 因此, 我们测量典型生物分子MD体系的模拟性能并确定相应的总硬件价格. 我们并没有针对当前的可用硬件进行全面评估, 我们仅仅是为了发现具有卓越性价比的硬件, 这是本研究中使用的效率指标, 用于GROMACS 2018版本的MD代码.
由于我们的研究优先考虑生成轨迹的效率和总吞吐量(假设有大量并发模拟), 因此我们不考虑生成单个轨迹尽可能快的用例. 而后者也可能很重要, 例如, 在探索性研究中, 更快的模拟需要很强的标度行为, 这总是要付出代价的, 因为模拟速度和并行效率之间具有内在的权衡. 同时, 运行大量的独立或耦合不强的模拟是一个广泛使用并日益重要的用例. 由于模拟性能的不断提高, 许多优化过的MD代码(如GROMACS)即使没有大规模并行化, 轨迹的生成速率也很高. 此外, 以前需要生成很长轨迹的问题现如今通常借助系综方法, 使用大量更短的轨迹来替代[11-15]. 因此, 具有单个快速互连的大型计算资源通常并不是必须的. 相反, 在这些实例中, 理想硬件是具有快速”孤岛”并且相互间具有更适度的互连. 事实上, 在这样的机器上, 某些情况下可以获得很快或更快的结果, 更重要的是, 可以获得更具成本效益的结果. 在我们的案例中, 考虑到当前的硬件限制和软件特性, 出于最终效率的原因, 快速”孤岛”由一组CPU核心和单个GPU表示.
除了性价比之外, 在评估系统时, 我们还考虑到以下两个标准: (1) 能耗, 因为它是轨迹成本的最大来源之一; (2) 机架空间, 这在任何服务器机房都是有限的. 在本文的一个章节中我们单独介绍了能耗, 而我们的硬件预选则隐含地考虑了空间要求; 对要考虑的服务器节点, 我们要求机架空间中的平均堆积密度至少为每高度单位U一个GPU: 具有4个GPU的4U服务器符合标准.
在使用GROMACS 4.6和2014年硬件的早期调查中[16], 我们发现优化的集群的模拟吞吐量通常是传统集群的两到三倍. 自2014年以来, 硬件一直不断发展, 并且以及对基本算法经进行了改进. 因此, 使用两个完全相同的MD测试系统, 我们更新原先的调查结果, 向读者指出对GROMACS 2018而言能获得最佳性价比的当前硬件[10, 17].
我们专注于硬件评估而不是如何优化GROMACS的性能, 因为对后者已经进行了广泛的讨论[16]. 如果没有额外说明, 我们原始论文中给出的大多数性能建议仍然有效. 有关特定GROMACS版本的特殊说明, 请参见在线用户指南中 Getting good performance from mdrun 这一部分。
GROMACS负载分配方案
GROMACS使用各种机制对可用资源上的计算工作进行并行化, 以便能获得最佳的硬件性能[10, 18]. 共享MD体系计算的进程(称为rank)是通过消息传递接口(MPI)库进行通信的, 每个rank可以包含多个OpenMP线程. 如果可以, 每个rank可以有选择地在GPU上计算库仑和范德华相互作用(对势)的短程部分; 这个过程称为卸载, 如图5所示. 库仑相互作用的长程部分使用粒子网格Ewald(PME)方法[19]进行计算, 该方法可以只使用一部分rank进行以提高并行效率. 从2018版开始, PME也可以卸载到单个GPU上进行. 在并行化层次结构最低的级别上, 几乎所有对性能敏感的代码都利用了SIMD(单指令多数据)并行性.
2014年调查总结
为了说明过去五年中在实现方面和硬件方面的进步, 我们总结了先前调查的以下要点.
在我们最初的调查中[16], 对由12个CPU和13个GPU型号构成的超过50种不同的节点配置, 我们确定了硬件价格和GROMACS 4.6的性能. 特别是, 我们将消费级GPU与专业GPU进行了比较. 像NVIDIA的Tesla和Quadro型号的专业GPU通常用于计算机辅助设计, 计算机图像生成以及HPC. 消费级GPU, 如GeForce系列, 主要用于游戏. 它们便宜得多(最高差价达1000欧元, 而专业卡则高达几千欧元), 而且缺乏专业型号所提供的一些功能, 如内存和双精度浮点性能.
我们的两个主要基准系统(我们在本研究中继续使用), 第一个含有一个80 k原子的膜蛋白, 嵌入脂质双层中, 周围是水和离子(MEM); 第二个含有一个2 M原子的核糖体, 以及水和离子(RIB). 具体细节请参见表1. 对每个硬件配置, 我们通过扫描并行化的参数, 如MPI rank数, OpenMP线程数和单独PME rank数, 确定了每个系统运行单个模拟的最快设置.
| MD体系 | MEM[20] | RIB[1] | VES[21] | BIG |
|---|---|---|---|---|
| 粒子数 | 81,743 | 2,136,412 | 72,076 | 2,094,812 |
| 体系尺寸(nm) | 10.8×10.2×9.6 | 31.233 | 22.2×20.9×18.4 | 142.4×142.4×11.3 |
| 时间步长(fs) | 2 | 4 | 30 | 20 |
| 截断半径(nm) | 1.0 | 1.0 | 1.1 | 1.1 |
| PME网格间距(nm) | 0.12 | 0.135 | – | – |
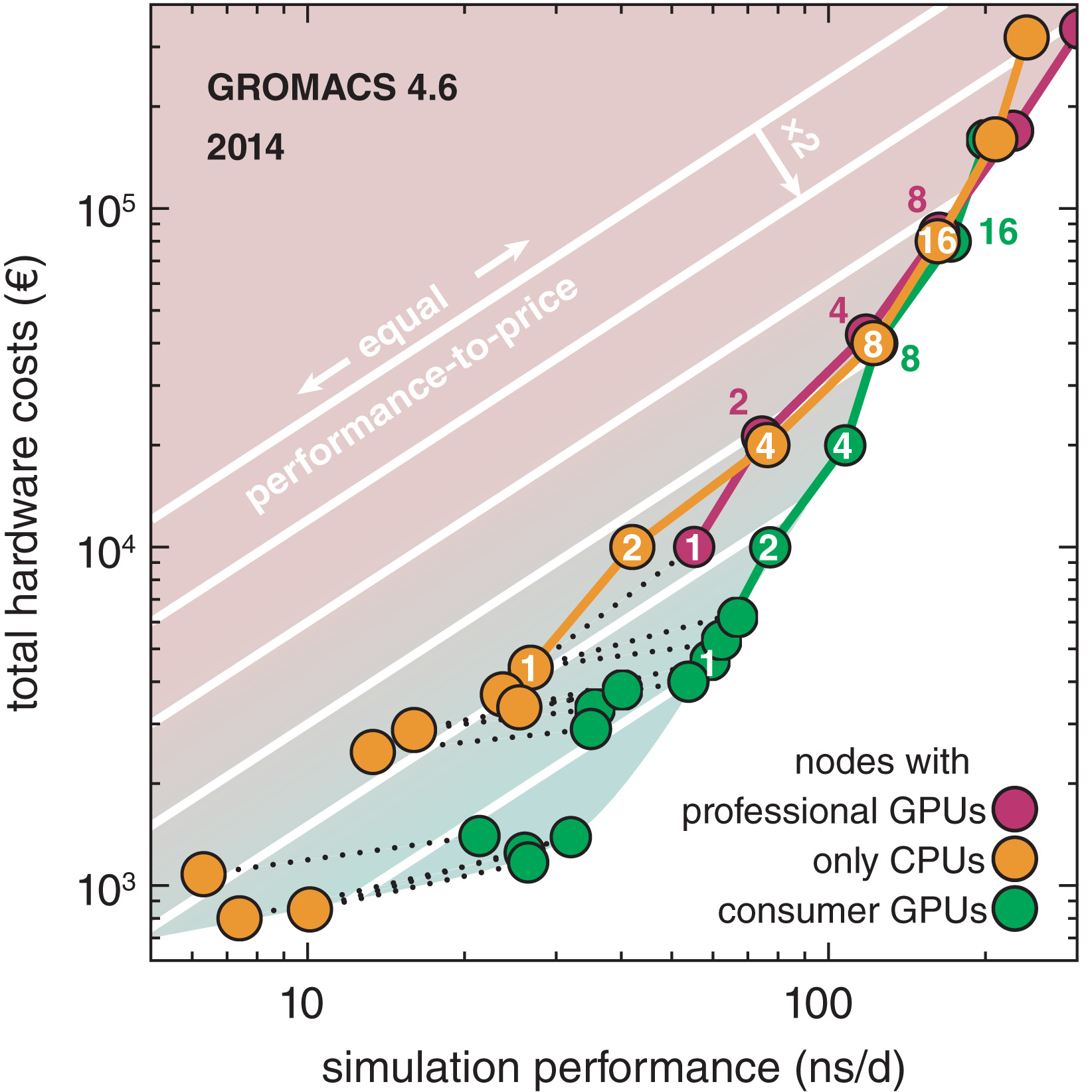
图1: 我们以前调查的摘要, 节点基于2014年的可用硬件, 使用GROMACS 4.6进行测试[16]. 三种不同类型节点的硬件成本与MEM基准性能(圆)的比较: 纯CPU节点(橙色), 具有专业Tesla GPU的节点(紫色)和具有消费级GeForce GPU的节点(绿色). 虚线将GPU节点与其CPU连接起来. 由彩色线连接的圆圈表示由该节点类型构建的集群, 圆圈中的数字表示这些节点中有多少参与了基准测试. 白线是具有相等性价比的等值线. 从一个等值线向下移动到下一个等值线性价比会变为原来的2倍(红色阴影区域=低性价比, 绿色阴影区域=高性价比)
我们从调查中得出的结论(图1)是, 只含单个CPU的节点和具有专业GPU的节点具有相对较低的性价比, 而消费级GPU的性价比可以提高到原来的2到3倍. 为节点增加第一个消费级GPU会极大地提供性价比, 而增加过多的GPU会降低性价比(例如, 以前论文的图6中将带有2个E5-2680v2的节点与具有2个和4个GTX980 GPU的节点进行了比较).
在多个节点上进行并行化以提高性能会导致性价比急剧下降(图1, 右上角). 因此, 对于总采样量比单个轨迹长度更重要的项目, 建议运行多个单节点模拟, 而不是运行一些多节点模拟.
2014-2018年硬件和软件的发展
硬件的发展
在过去五年中, GPU的计算能力显著提高(比较表2和图2). 最近的NVIDIA Turing架构GPU比我们在2014年测试的Kepler和Maxwell领先两到三代, 并且在此期间将单精度(SP)浮点性能提高到原来的三倍多. 这得益于半导体制造技术的飞跃, 将Kepler和Maxwell使用的28 nm晶体管工艺缩小到Volta和Turing的12 nm, 并使晶体管数量增加到五倍以上. 相比之下, 在同一时期, CPU制造从22纳米向14纳米迈进了一小步. 然而, 基于GPU的高效MD应用程序的性能在某些情况下甚至比单纯浮点性能所表明的好得多, 这得益于微体系结构的改进, 使得GPU更高效, 因此更适合于通用计算. 例如, 考虑受计算限制的非键对相互作用内核的性能(图3, 上). 早期GPU产品吞吐量的增长, 如从Tesla K40到Quadro M6000再到Quadro P6000, 可以很好地反映FLOP速率的增长(两者大约为1.9倍), Tesla V100显示了1.7倍的性能, 而SP FLOP速率的增益只有1.1倍(见图2和3中的紫色条). 与上述具有类似最大额定功率的专业GPU不同, 比较消费级GPU并没有那么简单. 然而, 在将Pascal GTX 1080Ti与Turing RTX 2080 GPU进行对比时, 类似的模式仍然很明显. 尽管FLOP大约降低了10%, 最大额定功率也会降低10%, 2080在非键和PME计算中分别快40%和29%. 在两代GPU中, 我们观察到使用GPU卸载的GROMACS计算内核, 计算非键对势相互作用和PME静电力的性能分别提高到6倍和4倍. 相比之下, 虽然CPU的理论FLOP速率的增加与GPU类似, 但微架构的改进, 如更宽的AVX512 SIMD指令集, 仅仅相对适度的提高了应用程序的性能, 即使对完全SIMD优化的代码(如GROMACS)也是如此.
| 类型 | 制造商 | 架构 | 计算单元 | Base-boost频率(MHz) | SP TFLOPS | ≈净价(€) |
|---|---|---|---|---|---|---|
| NVIDIA消费级GPU | ||||||
| GTX 680 | NVIDIA | Kepler | 1536 | 1006–1058 | 3.1–3.3 | – |
| GTX 980 | NVIDIA | Maxwell | 2048 | 1126–1216 | 4.6–5 | – |
| GTX 1070 | NVIDIA | Pascal | 1920 | 1506–1683 | 5.8–6.5 | 310 |
| GTX 1070Ti | NVIDIA | Pascal | 2432 | 1607–1683 | 7.8–8.2 | 375 |
| GTX 1080 | NVIDIA | Pascal | 2560 | 1607–1733 | 8.2–8.9 | 420 |
| GTX 1080Ti | NVIDIA | Pascal | 3584 | 1480–1582 | 10.6–11.3 | 610 |
| RTX 2070 | NVIDIA | Turing | 2304 | 1410–1710 | 6.5–7.9 | 450 |
| RTX 2080 | NVIDIA | Turing | 2944 | 1515–1710 | 8.9–10.1 | 640 |
| RTX 2080Ti | NVIDIA | Turing | 4352 | 1350–1545 | 11.8–13.4 | 1050 |
| AMD GPU | ||||||
| Radeon Vega 64 | AMD | Vega | 4096 | 1247–1546 | 10.2–12.7 | 390 |
| Radeon Vega FE | AMD | Vega | 4096 | 1382–1600 | 11.3–13.1 | 850 |
| NVIDIA专业级GPU | ||||||
| Tesla K40c | NVIDIA | Kepler | 2880 | 745–875 | 4.3–5 | – |
| Tesla K80 | NVIDIA | Kepler | 4992 | 562–875 | 5.6–8.7 | – |
| Quadro M6000 | NVIDIA | Maxwell | 3072 | 988–1152 | 6.1–7.1 | – |
| Quadro GP100 | NVIDIA | Pascal | 3584 | 1303–1556 | 9.3–11.1 | – |
| Quadro P6000 | NVIDIA | Pascal | 3840 | 1506–1657 | 11.6–12.7 | 4600 |
| Tesla V100 | NVIDIA | Volta | 5120 | 1275–1380 | 13.6–14.1 | 8000 |
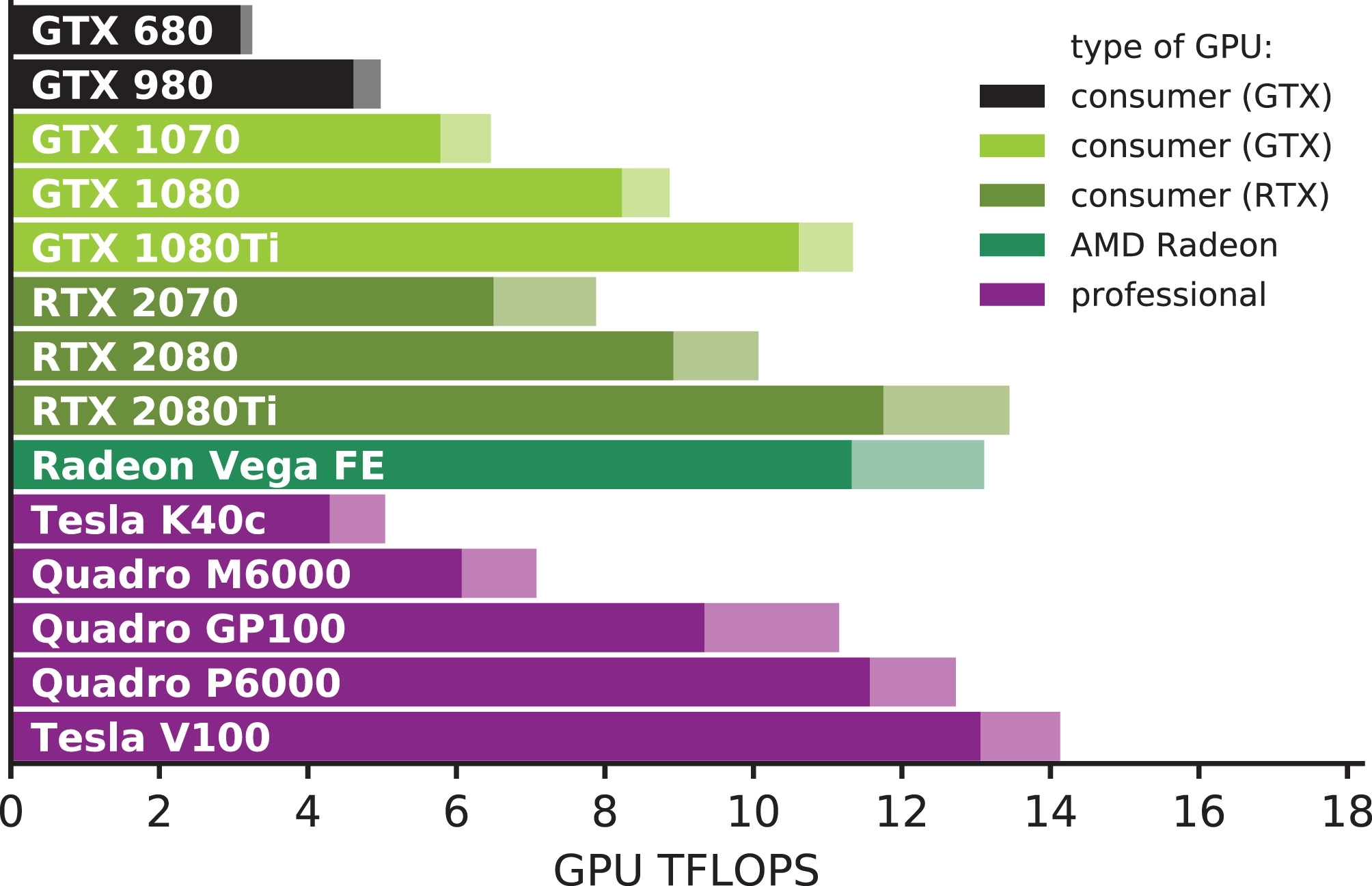
图2: 根据核心和时钟速率计算的所选GPU型号的原始单精度浮点性能(阴影区域描绘了运行在Boost/最大应用程序频率的浮点性能). 黑色: 2014年调查的一部分消费级GPU; 绿色阴影: 最近的消费级GPU; 紫色: Quadro和Tesla专业GPU.
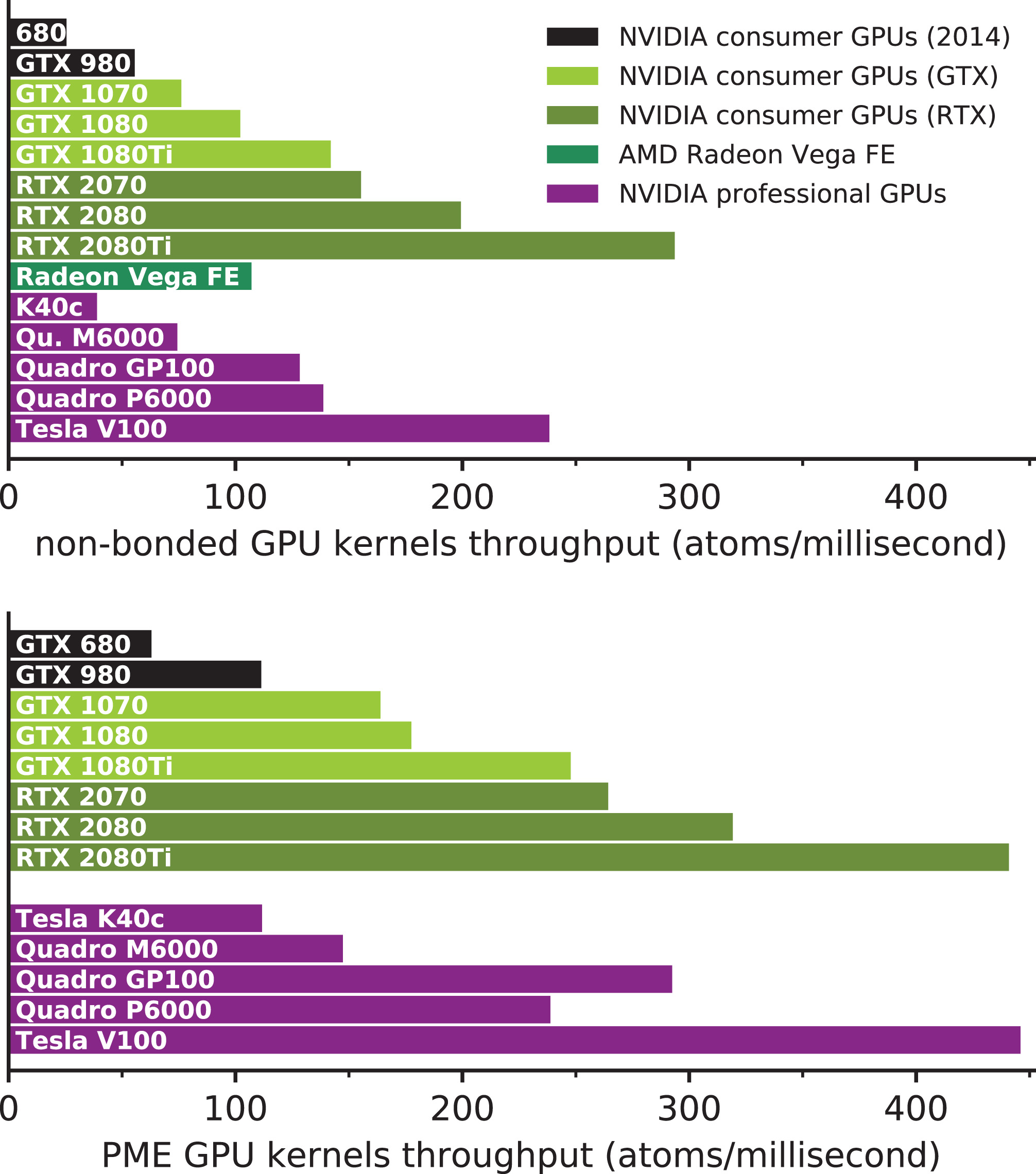
图3: GPU卸载计算的吞吐量: 本研究所用不同代和类别的GPU设备对短程非键相互作用(上)和PME长程静电(下)的表现. 颜色标识与图2相同. 计算吞吐量的单位为原子每毫秒, 这有助于与原始浮点性能进行比较. 测量是通过对内核执行(禁用并发)进行性能分析完成的, 使用的体系为384 k个原子的TIP3P水盒子(截断半径1.0 nm, PME网格间距0.125 nm, 时间步长2 fs), 这样可以比较具有不同标度行为的GPU在各自的峰值吞吐量下对两个内核的表现.
GPU制造和架构改进的融合已经导致CPU和GPU产生了显著的性能差距, 特别是对于像MD这样受计算限制的应用程序, 它们并不会严重依赖于双精度浮点运算. 此外, 由于计算机游戏行业的激烈竞争, 高性能消费级GPU性能功耗低的优势和合理的价格进一步加强了GPU在MD社区中的作用. GPU上应用程序的性能改进也导致了典型硬件平衡的变化, 这对使用基于卸载的异构并行化的应用程序非常重要, 也推动了GROMACS MD引擎进一步发展GPU卸载能力.
软件发展
在软件方面, 从我们之前的研究到目前的工作这段时间内, GROMACS一直在不断改进, 共有四个主要的版本: 5.0(2014年6月), 5.1(2015年8月), 2016(2016年8月)和2018(2018年1月). 这些版本在算法(改进了对相互作用缓冲区的估算), SIMD并行化(在PME中, 改进了成键, 约束, 更新了内核)和内核优化(改进了力的累积)以及广泛的多线程优化(如对每个线程成键力输出的稀疏求和)方面都有进步. 多年来致力于设计代码以增加节点内的并行性(更宽的SIMD单元, 更高的核心数和更多依赖加速器的计算节点)既是为了改进性能, 从而更好地利用现有硬件, 同时也是为了代码能够跟上硬件的进化, 这是一种对未来收益的投资.
两项重大改进使得2018版本的性能进一步提升. 首先, 发展了聚类配对算法[22]的双配对列表扩展形式, 其目标有两个: 减少配对搜索(和区域分解)的计算成本, 并在不需要手动调整参数的情况下获得最优的模拟性能. 双配对列表算法使得保持配对列表的时间更长, 同时避免了非键计算开销. 这是通过使用较长的适当缓冲的相互作用截断, 以更低的频率(每100-200个MD步骤)构建较大的配对列表来实现的. 通过使用基于短缓冲截断的频繁修剪步骤, 可以得到典型的存在周期为5-15个MD步骤(运行时会自动调整)的较小的配对列表, 然后将其用于计算配对相互作用. 较低频率的配对搜索显著提高了这种计算的性能, 而列表修剪避免了因大的缓冲而引入的计算额外配对相互作用的开销. 另外的好处是, 不再需要调整搜索频率来平衡这两个开销以获得最佳性能了.
第二个主要的改进是, 虽然GROMACS版本4.6, 5.x和2016只能将库仑和范德华相互作用的短程部分卸载到GPU, 但在2018版本中, PME网格部分也可以卸载到支持CUDA的设备(图5). 通过卸载更多工作, 可以改变GROMACS内部的计算平衡, 从而能够利用近年来硬件平衡的变化. 这种改进使得能够有效地利用具有更多和更强GPU的节点, 并且性价比显著高于在最近的硬件上使用旧的版本. 与此同时, 继续关注CPU和GPU上基于卸载的并行化方法和改进仍然很重要, 且有两个主要好处: (1) 它确保几乎所有的GROMACS功能仍然支持GPU加速(而不是将GPU的使用限制在移植到GPU上的所有功能特性的一部分). (2) 此外, 卸载允许最小化供应商锁定的风险, 当主要制造商的硬件只能使用专有工具, 非标准的工具和编程模型时(性能合理), 这是不可忽略的.
由于从2019版本开始才支持使用OpenCL卸载PME, 我们尚未在我们的基准研究中使用AMD GPU. 然而, 我们预计, 最近的AMD图形处理器会与相近价位的NVIDIA消费级GPU具有相同的竞争力, 正如非键内核性能(见图3)和性价比(图4)所展示的那样.
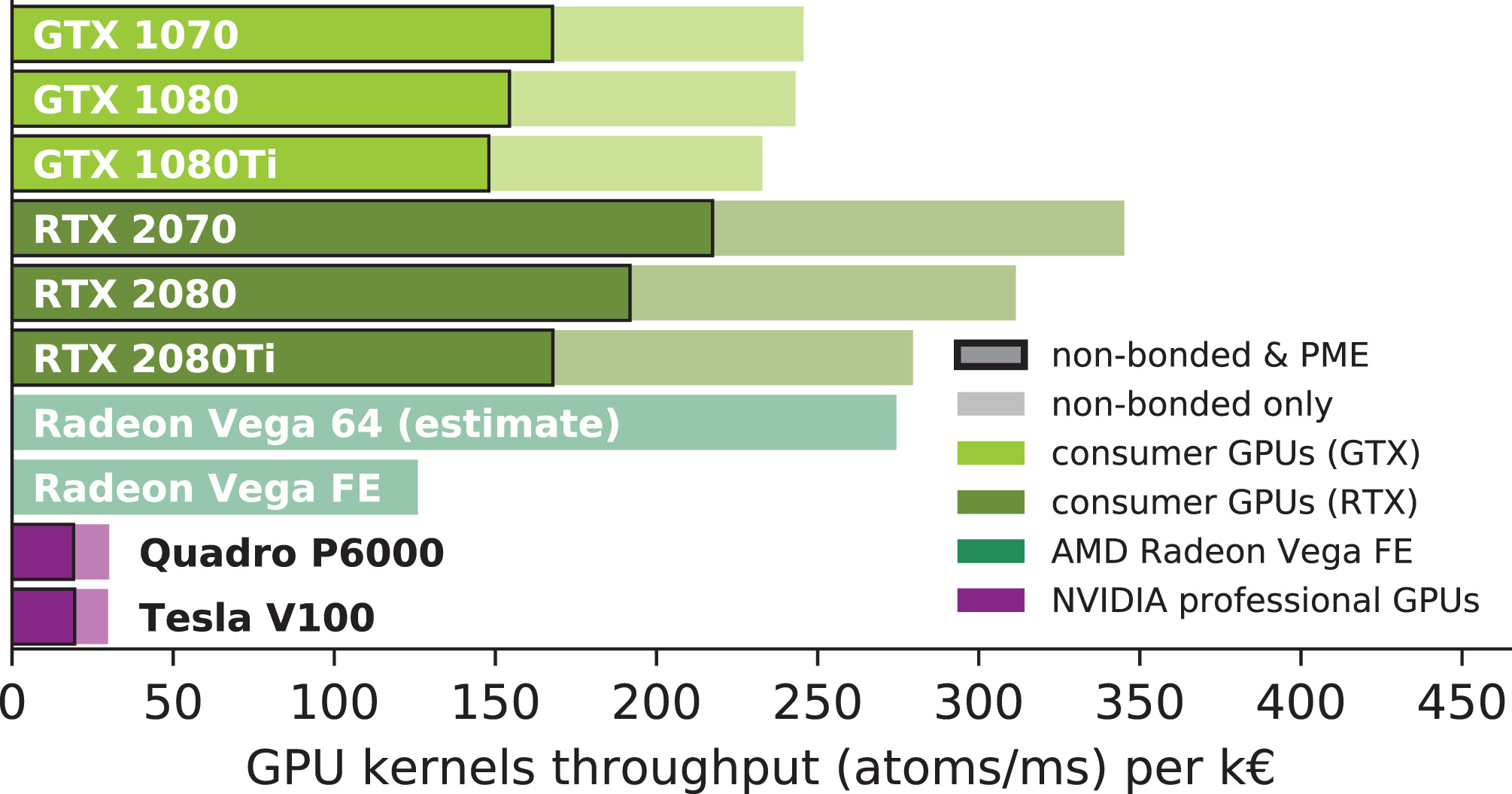
图4: 所选GPU型号的性价比指标, 根据GROMACS 2018 GPU内核性能除以表2中给出的价格得到. 每行的浅/阴影条表示仅来自非键内核的性价比, 暗条表示来自非键和PME内核的总性价比. AMD Vega 64的性价比是根据AMD Vega FE的吞吐量估算的, 但使用了Vega 64的价格.
卸载方法在GPU/CPU计算功率比平衡的情况下性能最好, 也就是说, 如果比值适合GROMACS模拟的典型要求(图5). 利用我们的基准测试和硬件选择, 我们可以确定最佳选择. 计算工作卸载得越多, 这种平衡向GPU偏移得越多, 如果GPU便宜, 就可以实现更高的性价比. 改用GROMACS 2018会使最佳CPU/GPU平衡比显著地偏向GPU, 如后文所示.
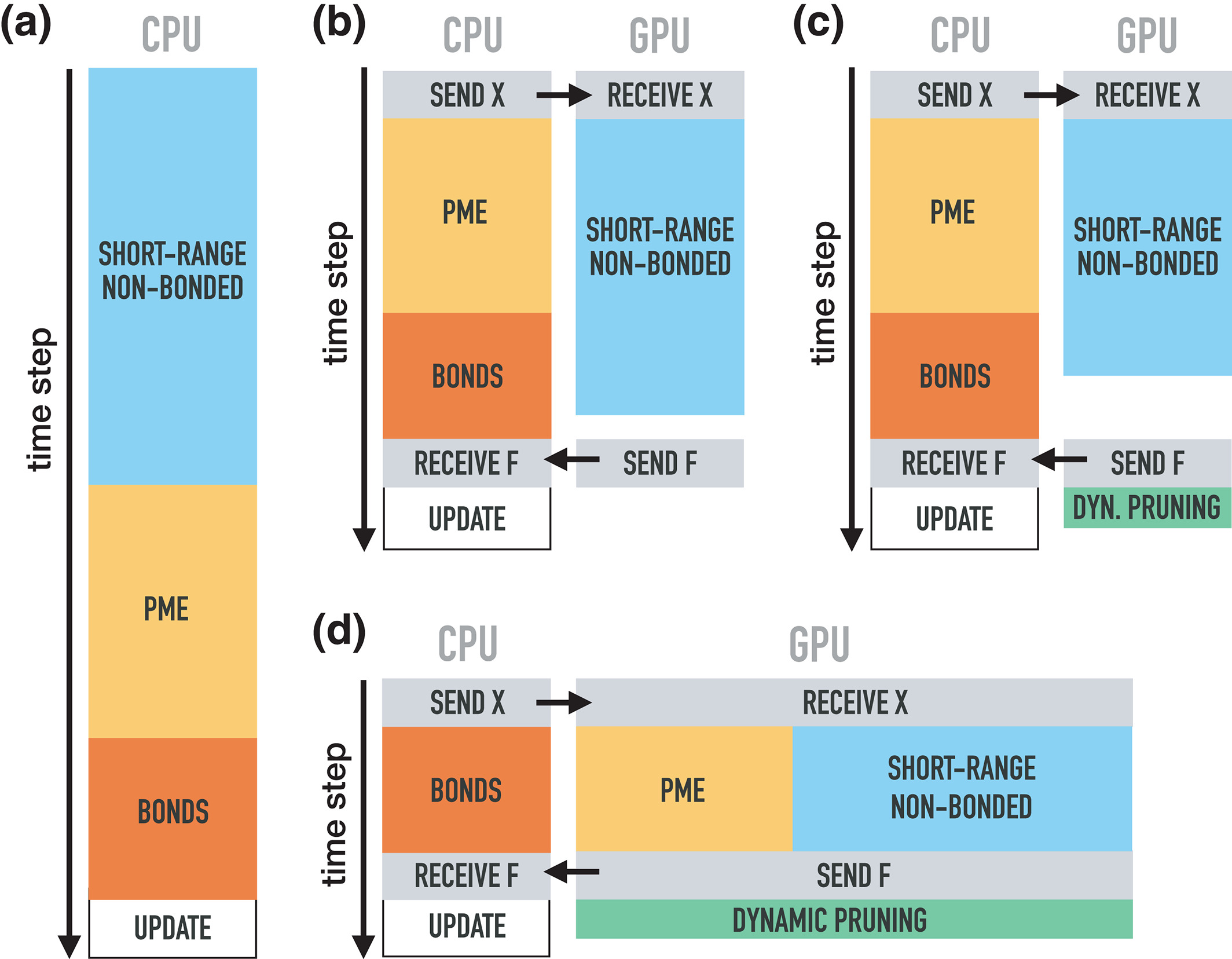
图5: GROMACS 4.6, 5.x和2016(b)以及GROMACS 2018(d, d)采用的不同卸载方案的比较. 不同颜色的框表示典型MD步不同的主要的力计算部分, 而灰色框表示CPU-GPU数据传输. 通过卸载MD步的计算密集部分并使用算法来优化并发CPU-GPU执行, 每个时间步运行所需的挂钟时间(黑色垂直箭头)会减少. a. 无GPU, 在CPU上计算短程非键相互作用(蓝色), PME(橙色)和成键相互作用(红色). 一旦得到了所有力, 原子位置就会更新(白色). b. 从4.6版开始, GPU可以计算非键力, 而CPU可以计算PME和成键力. 因此, 每个MD步的时间显著缩短, 而CPU和GPU(灰色)之间位置x和力F的通信代价很小. c. 2018版引入了双配对列表算法, i) 减少了计算短程非键相互作用的数量; ii) 降低了在CPU上进行配对搜索的频率(这里未展示). 这样做并没有增加计算开销, 因为动态列表修剪(绿色框)在GPU上进行, 而同时CPU更新位置(白色). d. 从2018版开始, 如果有足够的GPU处理能力, 还可以在GPU上计算PME, 从而进一步减少了每MD步的挂钟时间.
为GROMACS 2018组装最佳GPU节点
选择合适的硬件来组建性价比具有竞争力的节点本身就是个难题(图6). 让我们暂时只关注于GPU的性价比(图4). 如果考虑GROMACS GPU内核的原始吞吐量, Pascal架构GPU中的1080性价比最高, 而对于Turing GPU, 2070表现最佳. 然而, 考虑到具有最佳性价比的GPU并不总是最佳解决方案, 因为使用的GPU越多, 节点通常越昂贵(如图6的例子). 因此, 为了优化整个节点的组合性价比, 通常最好选择具有较低性价比但性能较高的消费级GPU.
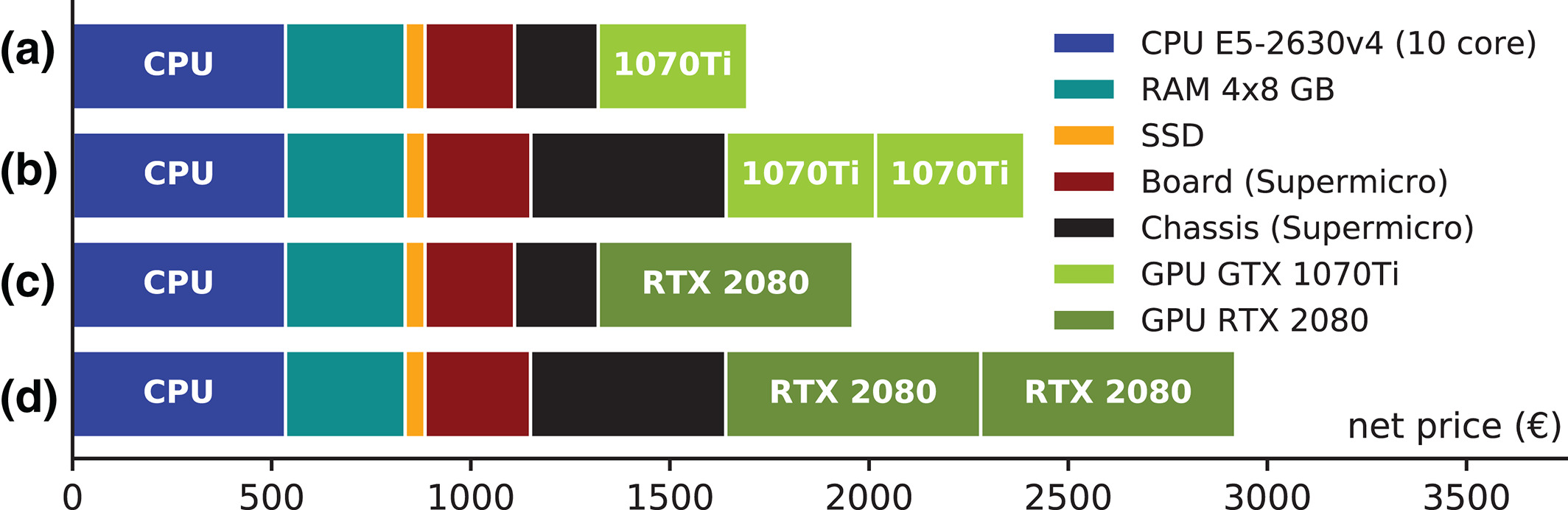
图6: 细分到各个组件的四种典型节点型号的成本. 对于节点a-d, CPU, RAM和SSD磁盘的成本是相同的, 但是, 对于两个带GPU的节点(b, d), 必须使用带有更强电源的机箱, 这使得节点明显更贵.
除了带有2个Tesla V100的Gold6148F×2节点(表3底部和图9顶部)之外, 我们没有构建和测试任何使用专业GPU的节点, 原因有两个: (i) 一块Tesla GPU的成本已超过了大部分带有消费级GPU的测试节点; (ii) 使用GROMACS进行MD模拟时, 使用专业GPU的额外好处(ECC可靠性, 保修)微乎其微, 与之性能相当的消费级型号普遍存在.
| U | 处理器 AMD/Intel | 插槽×核 | 主频(GHz) | 挂载GPU | MEM(ns/d) | RIB(ns/d) | ≈净价(€) | MEM性价比 (ns/d/122€) |
RIB性价比 (ns/d/1530 €) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | E3‐1270v5a | 1×4 | 3.6 | 1070 | 62.96 | 3.14 | 1300 | 5.78 | 3.61 |
| 1 | E3‐1270v5a | 1×4 | 3.6 | 1070Ti | 70.05 | 3.23 | 1395 | 6.13 | 3.54 |
| 1 | E3‐1270v5a | 1×4 | 3.6 | 1080 | 71.16 | 3.1 | 1440 | 6.03 | 3.29 |
| 1 | E3‐1270v5a | 1×4 | 3.6 | 1080Ti | 84.63 | 3.8 | 1630 | 6.33 | 3.57 |
| 1 | E3‐1240v6b | 1×4 | 3.7 | – | 11.7 | 0.69 | 1040 | 1.37 | 1.02 |
| 1 | E3‐1240v6a | 1×4 | 3.7 | 1070 | 68.72 | 3.48 | 1350 | 6.21 | 3.94 |
| 1 | E3‐1240v6a | 1×4 | 3.7 | 1080 | 78.04 | 3.48 | 1460 | 6.52 | 3.65 |
| 1 | E3‐1240v6a | 1×4 | 3.7 | 1080Ti | 95.45 | 4.38 | 1650 | 7.06 | 4.06 |
| 1 | E3‐1240v6b | 1×4 | 3.7 | 2080 | 110.69 | 4.85 | 1680 | 8.04 | 4.42 |
| 1 | E3‐1240v6b | 1×4 | 3.7 | 2080Ti | 133.26 | 5.77 | 2090 | 7.78 | 4.22 |
| 1 | Core i7‐6700Ka | 1×4 | 4.0 | 1070 | 67.69 | 3.28 | 1350 | 6.12 | 3.72 |
| 1 | Core i7‐6700Ka | 1×4 | 4.0 | 1080Ti | 92.52 | 4.03 | 1650 | 6.84 | 3.74 |
| 1 | Silver 4110a | 1×8 | 2.1 | 1080Ti | 97.63 | 5.27 | 1910 | 6.24 | 4.22 |
| 1 | Silver 4110a | 1×8 | 2.1 | 1080×2 | 131.17 | 6.98 | 2840 | 5.63 | 3.76 |
| 1 | Silver 4110a | 1×8 | 2.1 | 1080Ti×2 | 155.66 | 8.84 | 3220 | 5.9 | 4.2 |
| 1 | E5‐2630v4a | 1×10 | 2.2 | 1070 | 73.61 | 3.84 | 1630 | 5.51 | 3.6 |
| 1 | E5‐2630v4a | 1×10 | 2.2 | 1070Ti | 82.41 | 4.02 | 1695 | 5.93 | 3.63 |
| 1 | E5‐2630v4a | 1×10 | 2.2 | 1080 | 83.42 | 3.83 | 1740 | 5.85 | 3.37 |
| 1 | E5‐2630v4a | 1×10 | 2.2 | 1080Ti | 104.01 | 4.99 | 1930 | 6.57 | 3.96 |
| 1 | E5‐2630v4b | 1×10 | 2.2 | 2080 | 115.41 | 5.88 | 1960 | 7.18 | 4.59 |
| 1 | E5‐2630v4b | 1×10 | 2.2 | 2080Ti | 146.28 | 7.27 | 2370 | 7.53 | 4.69 |
| 1 | E5‐2630v4a | 1×10 | 2.2 | 1080Ti×2 | 179.51 | 8.58 | 2860 | 7.66 | 4.59 |
| 1 | E5‐2630v4b | 1×10 | 2.2 | 2080×2 | 201.33 | 10.13 | 2920 | 8.41 | 5.31 |
| 1 | Silver 4114a | 1×10 | 2.2 | 1070Ti | 81.31 | 4.49 | 1855 | 5.35 | 3.7 |
| 1 | Silver 4114a | 1×10 | 2.2 | 1080 | 82.89 | 4.34 | 1900 | 5.32 | 3.49 |
| 1 | Silver 4114a | 1×10 | 2.2 | 1080Ti | 103.9 | 5.57 | 2090 | 6.06 | 4.08 |
| 1 | Silver 4114b | 1×10 | 2.2 | 2080Ti | 147.29 | 7.85 | 2530 | 7.1 | 4.75 |
| 1 | Silver 4114a | 1×10 | 2.2 | 1080×2 | 142.7 | 7.29 | 3020 | 5.76 | 3.69 |
| 1 | Silver 4114a | 1×10 | 2.2 | 1080Ti×2 | 165.19 | 9.58 | 3400 | 6.07 | 4.31 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 1080Ti | 94.9 | 5.01 | 2440 | 4.75 | 3.14 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 2080 | 106.08 | 5.56 | 2470 | 5.24 | 3.44 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 1080Ti×2 | 172.62 | 9.16 | 3050 | 6.9 | 4.6 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 2080×2 | 196.73 | 10.08 | 3110 | 7.72 | 4.96 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 2080×3 | 267.51 | 12.79 | 3750 | 8.7 | 5.22 |
| D | Ryzen 1950Xb | 1×16 | 3.4 | 2080×4 | 332.83 | 14.07 | 4390 | 9.25 | 4.9 |
| 1 | Epyc 7401Pb | 1×24 | 2.0 | – | 28.71 | 2.28 | 3500 | 1 | 1 |
| 1 | Epyc 7401Pb | 1×24 | 2.0 | 1080Ti×2 | 191.66 | 9.49 | 4720 | 4.95 | 3.08 |
| 1 | Epyc 7401Pb | 1×24 | 2.0 | 1080Ti×4 | 369.06 | 16.96 | 5940 | 7.58 | 4.37 |
| 2 | Gold6148F×2c | 2×20 | 2.4 | V100×2 | 300.76 | 19.95 | 23,200 | 1.58 | 1.32 |
| 2 | Gold6148F×2c | 2×20 | 2.4 | V100×2 (4R) | 393.32 | 27.27 | 23,200 | 2.07 | 1.8 |
|
U: 需要的机架空间(每节点计), D为桌面机箱. 性价比进行了归一化以便其值≥1. a: 使用CUDA 8.0 + GCC 5.4 + Intel MPI 2017. b: 使用CUDA 9.1 + GCC 6.4 + Intel MPI 2017. c: 使用CUDA 10.0 + GCC 6.4 + Intel MPI 2018. | |||||||||
方法
本研究的主要部分使用了与2014年调查相同的两个基准输入文件(表1), 以便于新旧硬件和软件之间的比较.
软件环境
对GROMACS进行基准评估时, 使用了每个版本的最新版. 其他的所有基准测试均使用GROMACS 2018进行, 编译时将针对Intel CPU启用了AVX2_256 SIMD指令, 针对AMD CPU启用了AVX2_128 SIMD指令(表4除外, 其中使用了AVX_256以反映硬件功能). 此外, 由于4.6版本的SIMD内核不支持AVX2_256指令集, 我们使用了AVX_256并添加了 -mavx2 -mfma 编译器优化标志以便生成AVX2指令.
| U | 处理器 Intel | 插槽×核 | 主频 (GHz) |
挂载GPU | MEM (ns/d) |
RIB (ns/d) |
≈净价 (€) |
MEM性价比 (ns/d/122€) |
RIB性价比 (ns/d/ 1530€) |
|---|---|---|---|---|---|---|---|---|---|
| 使用旧GPU的现存节点 | |||||||||
| 1 | E3‐1270v2 | 1×4 | 3.5 | 680 | 26.9* | 1.6 | 0 | ‐ | ‐ |
| 升级GPU | |||||||||
| 1 | E3‐1270v2 | 1×4 | 3.5 | 2080 | 91.7 | 4 | 640 | 12.4 | 5.7 |
| 使用旧GPU的现存节点 | |||||||||
| 2 | E5‐2670v2×2 | 2×10 | 2.5 | 780Ti×2 | 104.8* | 6.7 | 0 | ‐ | ‐ |
| 升级GPU | |||||||||
| 2 | E5‐2670v2×2 | 2×10 | 2.5 | 1080×2 | 163.4 | 7.8 | 840 | 8.5 | 1.9 |
| 2 | E5‐2670v2×2 | 2×10 | 2.5 | 1080Ti×2 | 208.4 | 10.2 | 1220 | 10.4 | 4.3 |
| 2 | E5‐2670v2×2 | 2×10 | 2.5 | 1080Ti×4 | 361.2 | 17.9 | 2440 | 12.8 | 7 |
| 使用旧GPU的现存节点 | |||||||||
| 2 | E5‐2680v2×2 | 2×10 | 2.8 | K20Xm×2 | 83.2* | 5 | 0 | ‐ | ‐ |
| 升级GPU | |||||||||
| 2 | E5‐2680v2×2 | 2×10 | 2.8 | 1080Ti×2 | 212.7 | 10.1 | 1220 | 12.9 | 6.4 |
| 2 | E5‐2680v2×2 | 2×10 | 2.8 | 2080×2 | 237.7 | 11.5 | 1280 | 14.7 | 7.8 |
| 2 | E5‐2680v2×2 | 2×10 | 2.8 | 2080×4 | 409.6 | 20.3 | 2560 | 15.6 | 9.2 |
在没有或只有一个GPU的节点上, 使用了GROMACS的内置线程MPI库, 而在多GPU节点上使用了Intel MPI 2017. OpenMP支持始终开启. 此外, GROMACS还链接到便携式硬件局部性库hwloc[23]1.11版. 在没有GPU的节点上, PME所需的FFT在CPU上计算. 因此, 我们使用使用了FFTW 3.3.7[24], 编译时GCC 4.8启用了选项 --enable-sse2 --enable-avx --enable-avx2, 这些推荐选项可以获得GROMACS的最佳性能. 在GPU节点上, CUDA cuFFT自动与PME卸载一起使用.
所有硬件都在相同的软件环境中进行测试, 使用Scientific Linux 7.4作为操作系统公共映像启动节点(Gold6148/V100节点除外, 它运行SLES 12p3, 进行GROMACS评估基准测试时使用了Ubuntu16.04服务器版).
使用GCC 5.4和CUDA 8.0或GCC 6.4和CUDA 9.1编译的GROMACS用于主要研究, 而在GROMACS评估部分使用GCC 7.3和CUDA 10进行编译.
编译器选择和CUDA版本的影响
为了评估所选GCC/CUDA组合对性能的影响, 我们在完全相同硬件上运行了MEM基准测试, 但同时使用了两种CUDA/GCC组合. 在具有两个E5-2670v2 CPU和两个GTX 1080Ti GPU的节点上, 对我们的MEM基准测试, 在GCC 6.4/CUDA9.1上比GCC 5.4/CUDA8快3.5%(10次运行平均). 在配备GTX 1070的E3-1270v2 CPU上, 大约快4%, 而在配备E5-1650v4和GTX 980的工作站上大约快1.5%. 为了在比较硬件时校正这种影响, 使用较旧的GCC/CUDA组合所测量的性能会乘以1.025.
使用CUDA 9.1和CUDA 10.0之间的性能差异是以类似的方式确定的, 结果小于0.5%, 我们没有校正这个小的影响.
GROMACS性能评估基准
对于GROMACS评估基准测试(图7和8), 使用了专门为评估不同代码版本的性能而设计的数据收集协议. 所有运行所用的GPU都连接到所用CPU的PCI总线(或者, 在图8中当使用两个CPU时, 连接到运行主线程所在的第一个CPU). 每个核心使用两个CPU线程, 通过附着线程的HyperThreading进行性能分析.
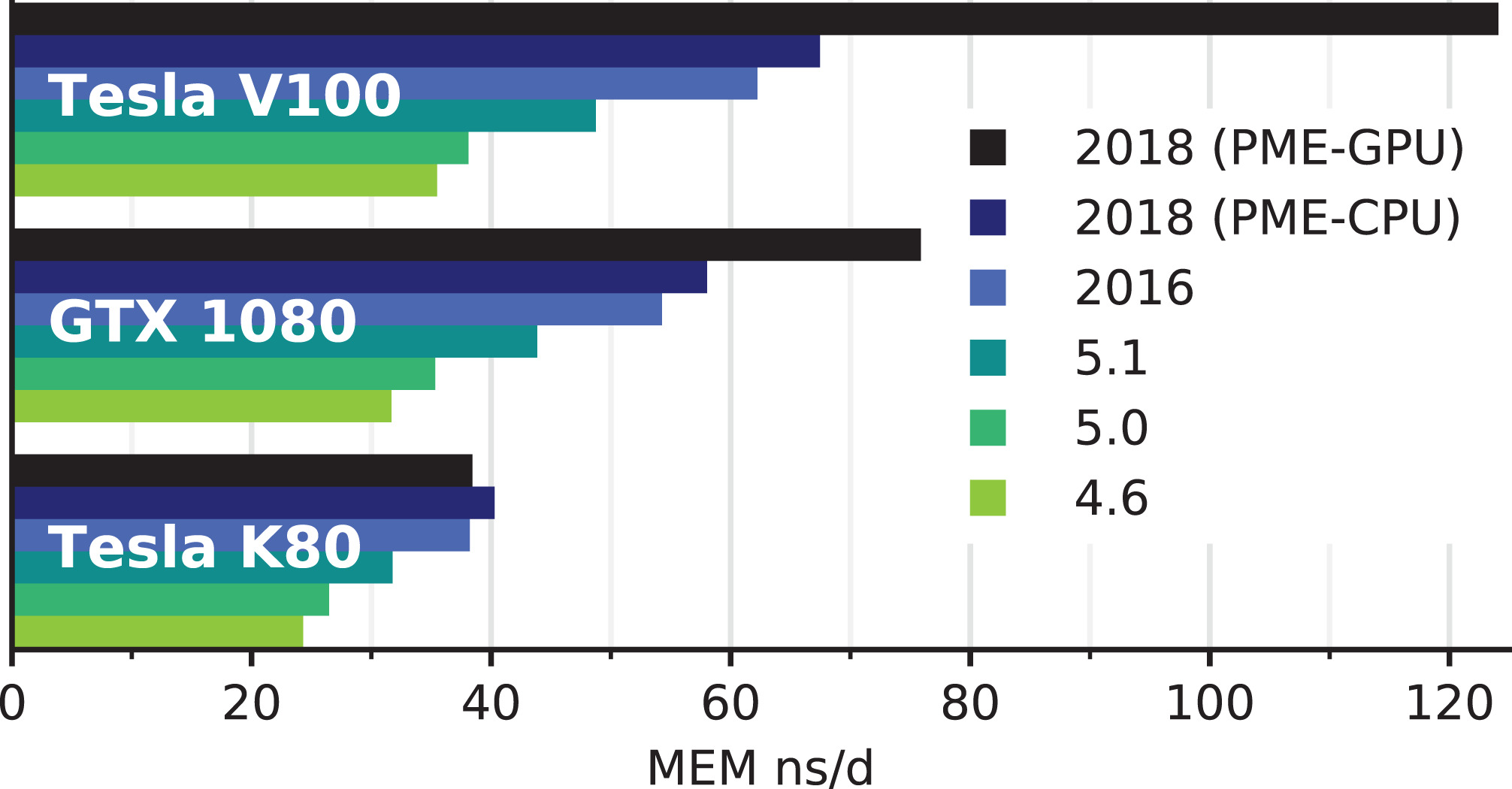
图7: GPU节点上GROMACS 4.6-2018版的性能的演变. 在所有实例中, 短程非键相互作用都卸载到GPU, 对于2018版, 也可以将PME网格计算部分卸载到GPU(最顶部的黑条). Tesla V100和GTX 1080 GPU挂载到一个带有两个Xeon E5-2620v4处理器(2×8核)的节点上. Tesla K80 GPU挂载到一个带有两个Xeon E5-2620v3处理器(2×6核)的节点上.
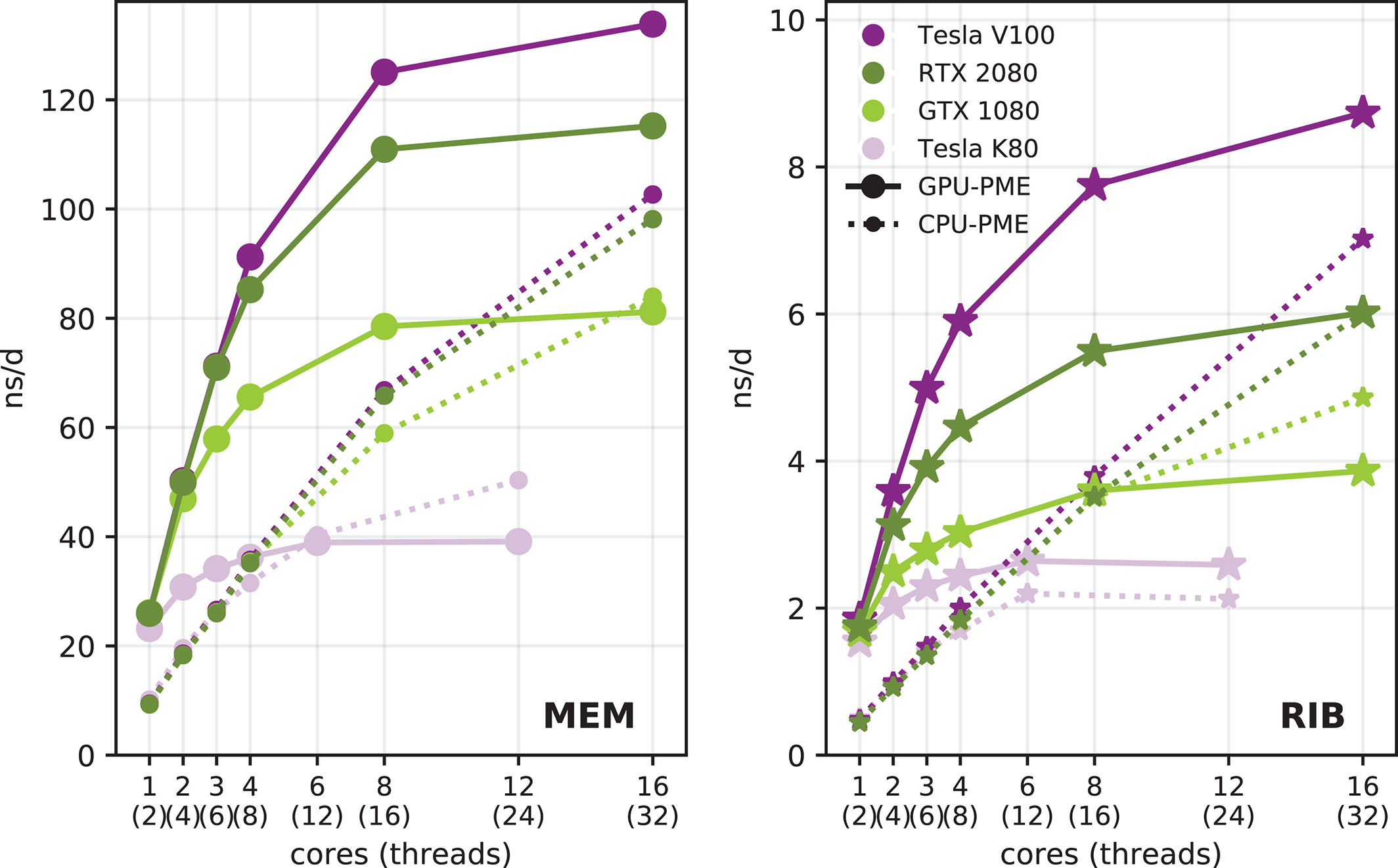
图8: GROMACS 2018性能与每个GPU使用CPU核心的关系. GTX 1080, RTX 2080和Tesla V100卡安装在带有Xeon E5-2620v4处理器(2×8核)的服务器节点上, 而Tesla K80安装在带有两个E5-2620v3处理器(2×6核)的节点上. 实线表示PME卸载到GPU时的性能, 而带有较小符号的虚线表示使用CPU计算PME时的性能(水平轴给出核心数目).
为了评估每个GPU所用CPU核心数对性能的影响(图8), 我们使用的CPU仅在核心数上有所不同, 其他情况完全相同. 我们使用单个CPU模型来模拟这种情况, 也就是运行时只使用CPU可用核心的一部分. 然而, 对于当前的CPU, 当只使用一部分核心时, 会增加工作核心的时钟频率. 这样进行比较就不公平了. 因此, 我们要确保未运行基准测试的核心同样保持忙碌, 这是通过在这些核心上同时运行仅使用CPU的GROMACS(使用与基准测试相同的输入体系)达到的. 这样所有核心都使用大致相同的时钟频率, 而与基准测试运行的核心数无关[^1]. 评估时, GROMACS基准测试会重复运行三次, 取平均值.
^1: 注意, 使用这种方法, CPU上的两个GROMACS运行会共享最后一级缓存. 因此, 所得测量结果与关掉不使用的CPU, 并将所有运行CPU的主频固定为同一个值的情况下所得的结果并不完全等价. 后一种做法提供了具有少数核心, 不合实际的缓存量情况下的基准.
最后, 除测试之外的所有编译和运行设置都保留其默认值或自动调整值(包括配对搜索频率和CPU-GPU负载均衡).
测定节点的性能
可以通过各种方式评估不同型号节点的性能. 而且, 不同的基准测试会给出不同的硬件排名. 我们对基准测试流程和由此得到的硬件排名的要求是: (1) 基准测试应该与预期的硬件使用密切相关; (2) 整体计算能力(例如, 将两个节点的硬件组件组合到一个节点中), 这可以节省价格和机架空间, 不应该受到限制.
我们提出第二个要求的动机如下: 假设你将 (a) 两个单插槽节点(各有一个CPU X和一个GPU Y)与 (b) 一个双插槽节点(带有两个CPU X, 两个GPU Y)进行比较, 预计(a)和(b)的总体性能是相同的, 因为两个独立的模拟总是可以在(b)上运行.
符合这两个要求的基准测试流程是: 在具有N个GPU的节点上并行运行N个模拟, 每个使用1/N的可用CPU核心或硬件线程, 并报告整体性能, 也就是说单个模拟的性能之和. 使用GROMACS的-multidir命令行参数很容易完成这个流程. 因为在初始阶段, 负载均衡机制尚未找到其最佳状态, 因此, 对总共n~tot~个时间步的性能测量, 我们会排除前n个时间步. 对于MEM和VES基准测试, 我们使用n=15k, n~tot~=20k, 而对于RIB和BIG基准测试, 我们使用n=8k, n~tot~=10k.
在只有一个GPU的单插槽节点上, 使用与可用核心(或硬件线程)一样多的OpenMP线程的单个进程通常是最快的, 因为可以避免MPI和区域分解引入的开销[16, 17]. 因此, 先前的调查和本研究的单GPU基准测试是可以进行比较的, 而在多GPU节点上, 新的基准测试流程预计会得到比2014年的单一模拟性能更高的整体性能.
功耗测量
我们使用Linux程序ipmi-sensors 1.5.7版(http://www. gnu. org/software/freeipmi/)和ipmitool 1.8.17版(https://github. com/ipmitool/ipmitool)测量节点的功耗. 在某些节点上, 例如在不支持通过ipmi读取功率的Ryzen工作站上, 我们使用了VOLTCRAFT Power Monitor Pro. 在所有情况下, 我们计算了60个单独的功率数据的平均值, 功率数据之间的时间差为1秒. 在测量功率期间, 使用相同的设置运行RIB基准测试以便获得性能数据.
使用Martini进行粗粒化模拟
为了检查全原子基准测试的结果可以在多大程度上用于粗粒化模拟, 我们增加了使用Martini[25, 26]力场的基准测试. 对于Martini力场, 粒子密度低于全原子力场的, 静电相互作用通常不使用PME计算. 因此, 尚不清楚粗粒化模拟的最佳硬件是否与原子模拟的相同.
为了便于与全原子系统进行比较, 我们选择了粒子数目相近的粗粒化系统, 见表1. 小的Martini基准系统 VES 是水中的POPE囊泡, 总共有72,076个粒子, 尺寸与MEM原子基准系统相当. 它是
根据使用GPU进行Martini模拟的建议, 我们使用了New-RF模拟参数设置[28, 29]. GROMACS自2018版起, 引入了双配对列表算法(见图5C), 我们将邻区搜索间隔从20(New-RF参数设置所用)增加到50步(内部配对列表存在周期为4步)以提高性能.
结果
对GROMACS性能发展的评估
如图7所示, 由于前面所述的算法改进和优化, 自我们之前的研究以来, 对4.6和2016版之间的最初四个版本, 在先前的硬件(例如Tesla K80)上模拟性能提高了65%, 在新一点的硬件(例如GTX1080和Tesla V100)是提高达75%-90%. 对在CPU上使用PME的2016和2018版之间, 我们测量得到了6%-9%的性能提升(图7中的浅蓝色条和深蓝色条), 这主要归功于动态修剪算法. 我们预计这种优势会随着未来GPU硬件的发展变得更大, 因为计算时GPU卸载越快, 该算法的好处就越大. 对于给定的基准测试系统和服务器设置, 我们观察到, 使用最新GPU时额外的PME卸载可以提升35%-84%的性能(见图7中的黑条). 同时, 在传统硬件设置上, 卸载到老一代的Tesla K80会导致速度变慢. 为了更好地理解这种性能的改变, 我们下面将探讨GROMACS 2018中异构PME卸载代码的性能特性.
我们的评估基准测试是在代表GPU密集设置的服务器上进行的, 这些服务器由具有相当适度性能的Xeon CPU和快速加速器组成. 一般而言, 这对GROMACS具有挑战性, 这可以从性能与所用核心数的强烈依赖关系看到(图8中的虚线). GROMACS 2018开发的主要性能目标之一是, 在平衡硬件上达到接近先前卸载方案(仅限非键)的峰值模拟速度, 但GPU只使用少数CPU核心. 在我们的基准测试硬件设置中, GTX 1080(图8中的浅绿色曲线)与E5-2620v4的大约12-14个核心相结合可以认为是平衡设置. 对于这两个系统, 每个GPU只使用四个核, PME卸载功能可以分别达到无卸载峰值的80%和90%.
2016版需要许多快速核心才能在CPU和GPU之间实现良好的负载平衡, 而在2018版中, 在大多数情况下, 像我们的基准测试系统那样, 只有4-6个较慢(典型服务器)的核就足以达到>80%的峰值模拟性能(例如使用一个节点的16个核). 工作站的核心通常核心, 但很快. 相比之下, 服务器通常拥有比工作站更多但更慢的核心. 为了比较两种节点类型的原始CPU处理能力, 我们考虑”core-GHz”, 即核心数目乘以主频. 我们发现, 使用中到高端GPU, 10-15 “core-GHz”通常足以在典型的生物分子模拟任务(如我们所用的)中接近峰值性能. 但是, 如果在卸载非键和PME计算后CPU还有许多剩余工作要做(例如, 大量的成键相互作用或自由能计算设置), 可能需要更多的CPU核心才能实现最佳平衡. 此外, 当可以使用更大更快的GPU时, 这种平衡当然会发生偏移. 例如Tesla V100(或性能相近的GeForce RTX 2080Ti)在性能达到平台期(紫色线条)之前实际上确实需要大约8-10个核心, 相当于16-20 “core-GHz”. 然而, GPU尺寸的增加也为计算带来了挑战: 大型设备难以饱和, 无法通过像MEM基准测试等常见工作负载获得峰值吞吐量, 这就是为什么Tesla V100的优势相对于RTX 2080较小, 尤其是与更大的RIB基准测试(图8中的紫色和深绿色线)进行比较时.
PME卸载的另一个好处是, 可实现的峰值性能也会提高, 并且在使用快速GPU的情况下, 可以实现显著的性能提升(见图8中的深绿色和紫色线条), 这在以前使用较慢CPU的情况下是不可能实现的. 相反, 如果使用早期GROMACS版本的最佳CPU-GPU设置, PME卸载可能不会提高性能. 特别是在传统GPU硬件上, PME卸载通常较慢, 这反映在Xeon E-2620v3 CPU与Tesla K80基准测试中, 其中每个GPU大约使用5-6核心.
总之, 由于动态修剪算法和PME卸载的结合, GROMACS 2018版可以将更少和/或更慢的CPU核心与更快的GPU结合起来使用, 这特别适用于GPU密集型硬件的吞吐量研究. 如果使用的硬件接近2016版的平衡设置, PME卸载并不会带来显著的性能提升, 但新代码为使用进一步加速器升级提供了可能. 作为一个例子, 一个8核工作站的CPU(如AMD Ryzen 7 2700), 大约会与图8中的10-16个核心一样快, 当与GTX 1080一起使用时, PME卸载几乎不会提升性能, 即便使用RTX 2080, 改进也不大(假设工作负载与我们的相似). 但是, 为这样的工作站添加第二块GPU几乎会使性能翻倍.
运行MD的最佳硬件
表3和图9显示了我们得到的当前硬件排名. 总体而言, 与没有GPU的同类产品相比, 我们所测试的消费级GPU节点的性价比大致是3-6倍. 具有消费级GPU的新节点的性价比都非常相似; 大多数都小于1.5倍, 因此在双对数图中大致分布在一条等值线上(图9). 注意, 这种相似性来自我们的硬件筛选, 并不意味着任何具有消费级GPU的节点都具有相近的性价比. 有非常多可能的硬件组合我们没有考虑, 因为一个或多个单独组件的高成本从一开始就排除了它们性价比的竞争性.
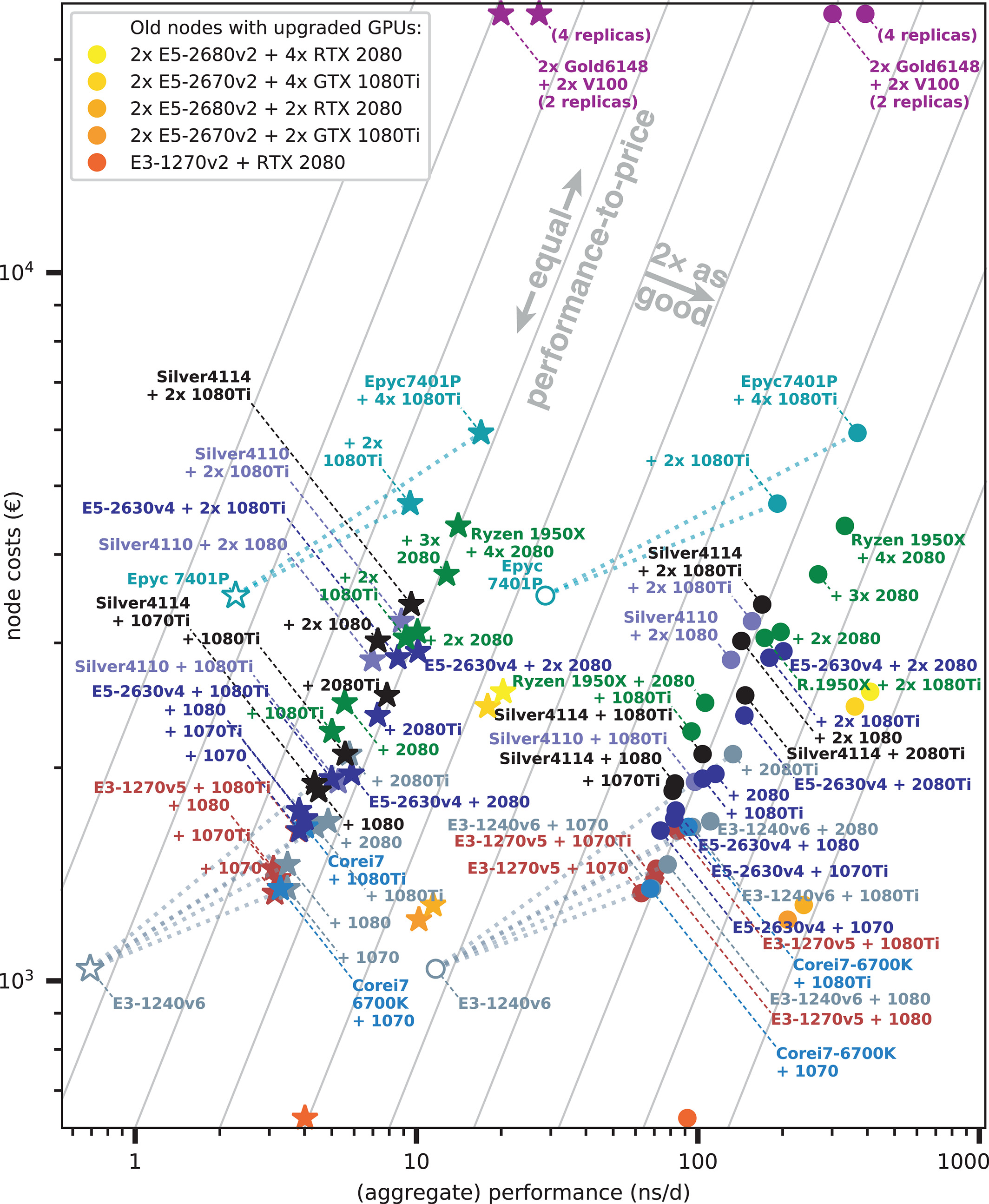
图9: (整体)模拟性能与节点净成本的关系. MEM(圆圈)和RIB(星星)根据CPU类型着色. 白色填充符号表示没有GPU加速的节点; 虚线将GPU节点与对应的CPU连接起来. 灰色: 具有与图1相同性价比的等值线, 右下方性价比更好. 升级了GPU的表4中的旧节点以黄色(图例)表示.
具有良好性价比的最便宜节点, 大约从1,400欧元起, 分别是Intel E3-1270v5, E3-1240v6或Core i7-6700K CPU结合GeForce 1070(Ti). 通过将E5-2630v4或Ryzen 1950X CPU与两个(或可能更多的)RTX 2080 GPU相结合, 能得到最佳性价比(以当前定价算), 起价为3,000欧元. 消费级GPU节点的最佳整体性能为AMD Epyc 24核心节点加四个1080Ti GPU.
考虑到空间要求, 表3中列出的大多数节点类型能够放到一个高度单位(U)的机架空间中. 一个例外是Ryzen Threadripper 1950X, 它只能在台式机箱中使用(如果安装在机架中, 大约会使用4U).
替代方案: 使用最新的GPU升级现有节点
如果不愿使用新硬件替换老的GPU节点, 一个可能更好的替代方案是只将GPU替换为功能更强大的新型GPU. 与旧版本相比, GROMACS 2018会将更多相互作用的计算卸载到GPU上, 因此GROMACS 2018需要GPU提供更多的计算能力, 但对CPU计算能力的需求更小. 因此, 几年前的CPU型号通常可以理想地与现代GPU一起使用.
例如, 作为2014年调查的一部分, 对具有两个K20Xm GPU的双十核节点, 通过使用最新的RTX 2080 GPU替换旧的GPU, 对于MEM基准测试所得的性能提升为原来的3.5倍. 表4列出了不同升级方案的性能提升. 每一部分的顶行给出了GROMACS 2018在旧节点上的性能, 而下行显示了升级GPU后的性能提升. 取决于具体的新旧GPU类型, 只需要花费比较低的成本购买GPU而不是整个节点, 就可以轻松地将整体性能提升为原来的两倍. 性能方面, 四个1080Ti GPU与新的EPYC 7401处理器(24核)一起使用, 或与两个旧的E5-2670v2处理器(2×10核)一起使用, 没有太大区别. 图9中的黄色和橙色符号显示了这些节点的性能与使用现代GPU升级的成本关系.
能源效率
为了确定节点在其使用周期内的总成本, 我们确定了其功耗. 假设能源和制冷的净成本为每千瓦时0.2欧元, 我们计算了所选节点型号的总成本, 即运行五年的硬件和能源成本之和(图10, 能源和冷却在五年中每一年的成本). 对于所考虑的节点型号和平均3-5年的寿命, 硬件和能源的成本是相似的. 然而, 一般情况下并非如此, 例如使用专业GPU, 硬件成本可轻松高达三倍.
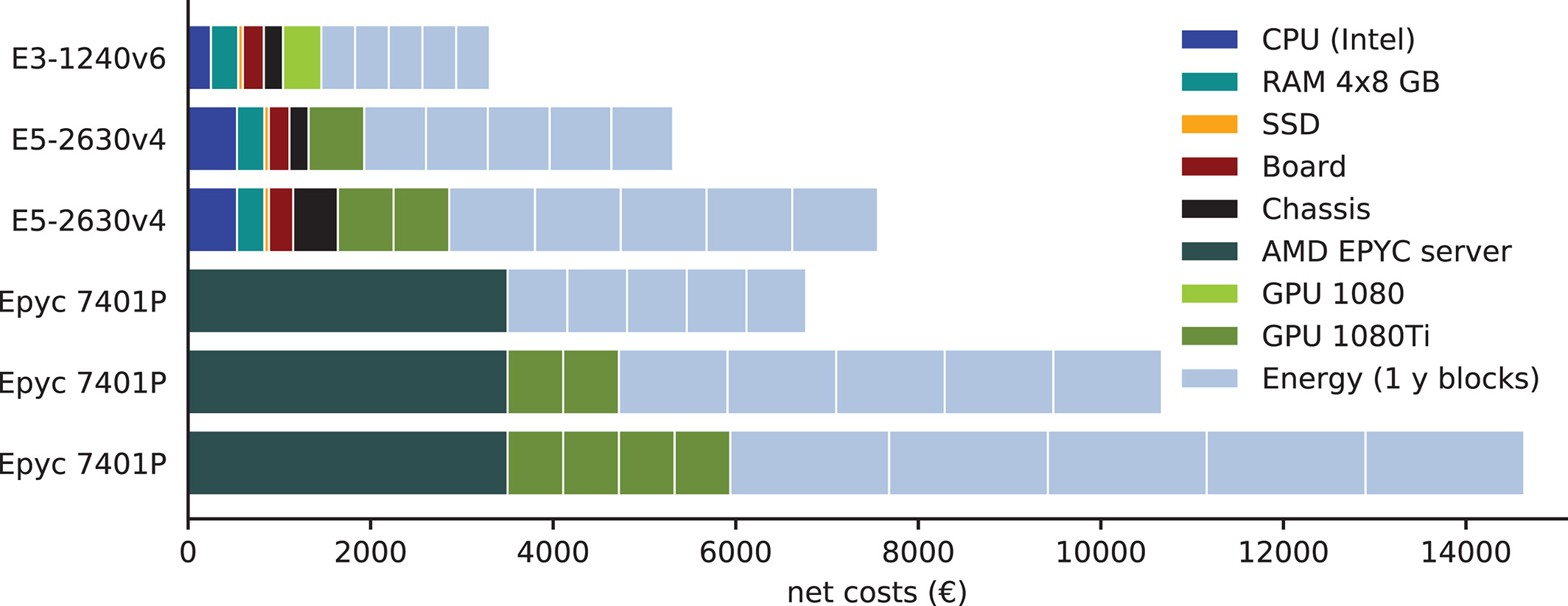
图10: 选定节点型号的总成本分解图, 能源和冷却成本以每千瓦时0.2欧元计, 节点寿命为五年.
图11显示了所选节点型号的能源效率与其GROMACS性能的关系. 使用GROMACS 2018, 除模拟性能更高外, GPU节点的每瓦性能是CPU节点的两倍以上.
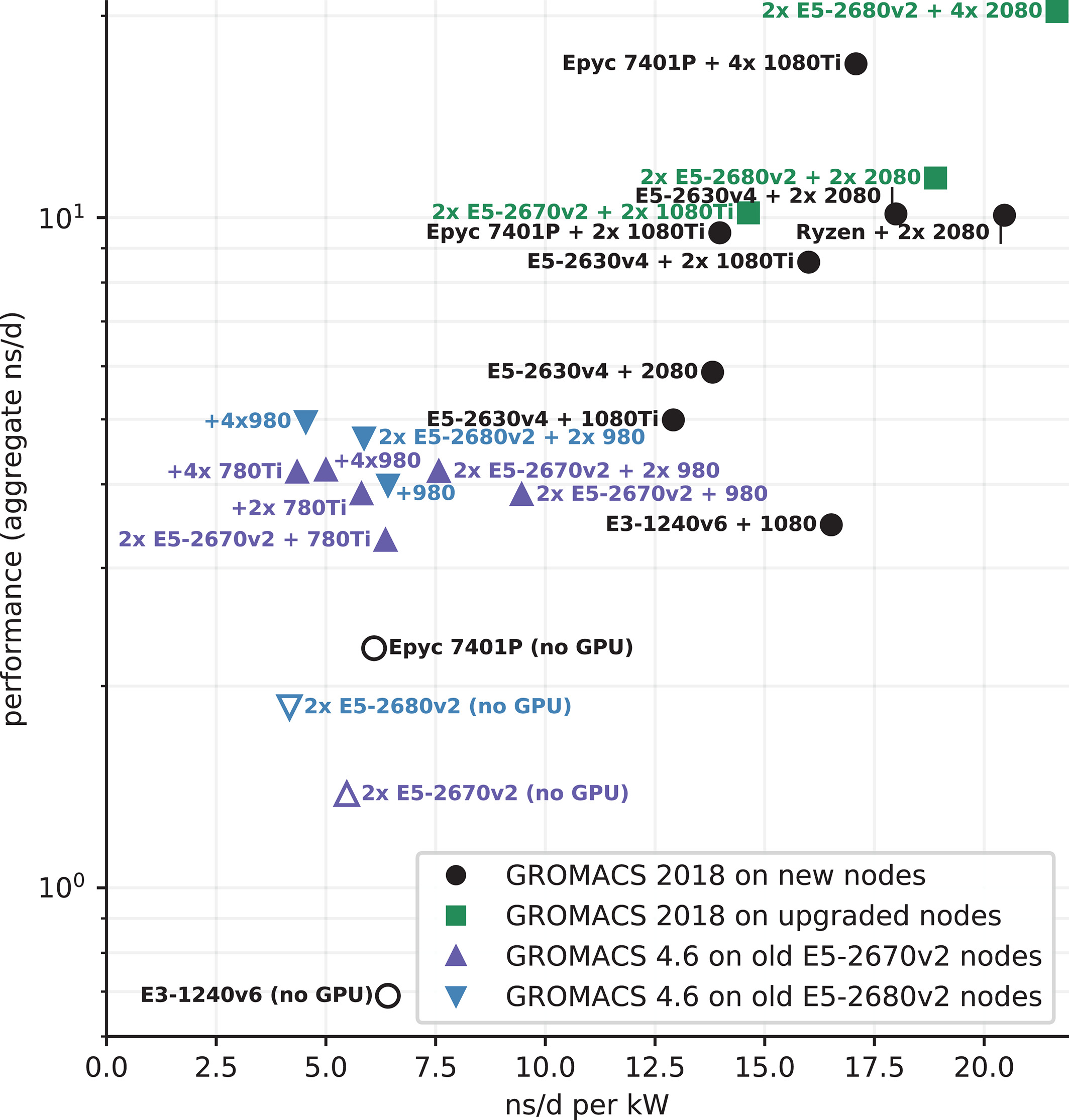
图11: 所选节点型号对RIB测试系统的性能与其能效的关系. 无GPU的节点(白色填充)性能和能效都低, 与GROMACS版本和CPU代数无关. 使用新GPU的GROMACS 2018(黑色和绿色填充符号)具有最佳能效.
通过将硬件和能源成本与生成的轨迹量联系起来, 我们得出了在不同节点型号上生成MD轨迹的总成本(图12). 我们得到了三个主要观察结果: (1) 在没有消费级GPU的节点上, 轨迹成本最高(图中标有星号); (2) 对于使用2014年硬件的GROMACS 4.6, 最佳GPU节点的轨迹成本是单纯CPU节点的0.5~0.6倍; (3) 使用GROMACS 2018和当前硬件, 该因子减少到约0.3.
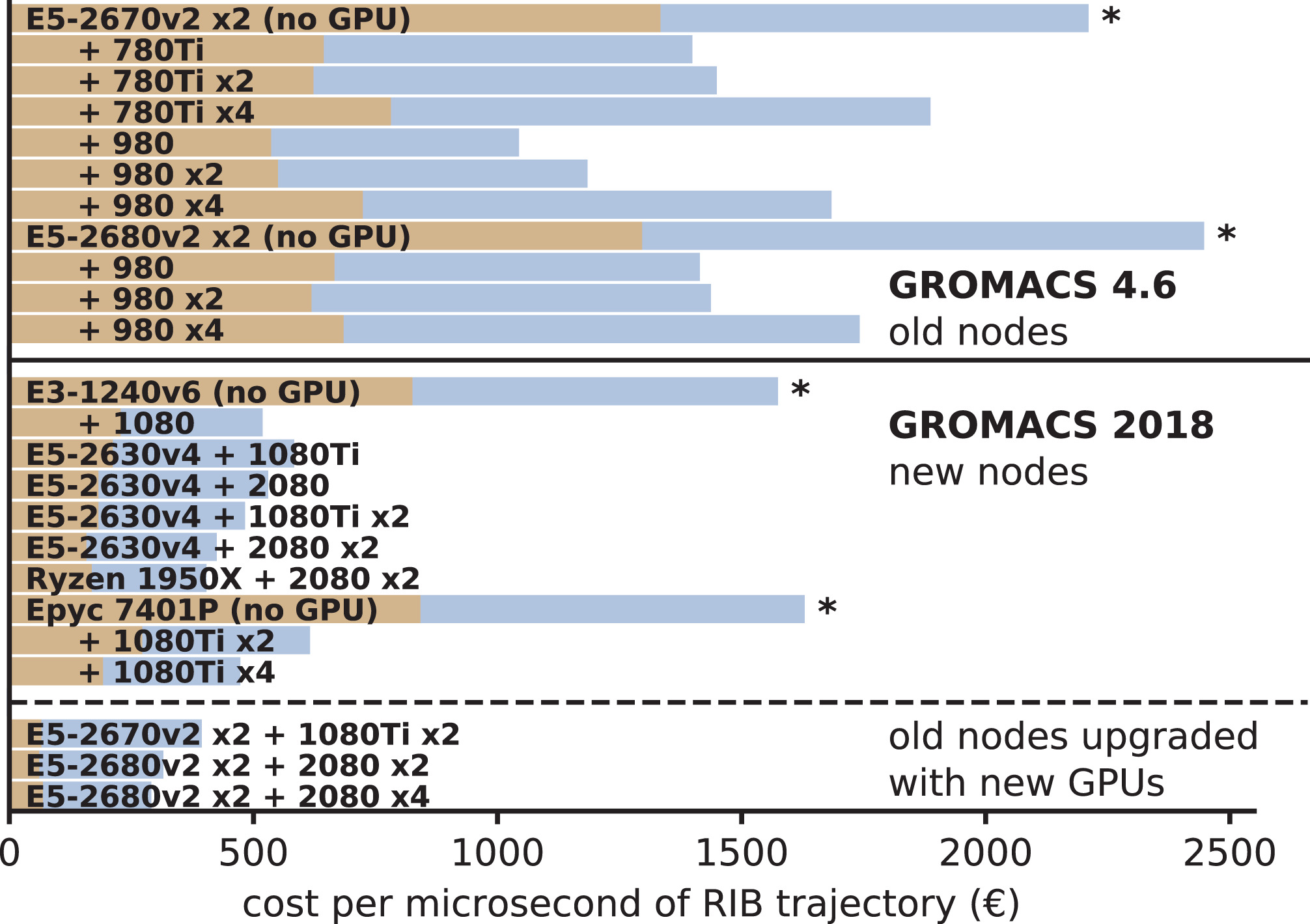
图12: 假定运行五年情况下, 对RIB基准测试体系所选节点型号的轨迹成本, 包括能源和冷却成本, 以每千瓦时0.2欧元计. 图的上半部分展示了2014年使用GROMACS 4.6[16]所得的结果, 下半部分给出了GROMACS 2018在最近的硬件, 使用新GPU升级的旧硬件(最低的三个条形图)上的结果. 无GPU节点的轨迹生产成本最高(星号).
粗粒化模型
我们使用全原子基准测试所用节点型号的一部分运行了Martini体系, 结果如图13所示. 总体情况与全原子基准测试结果(图9)非常相似, 但有一些差别.
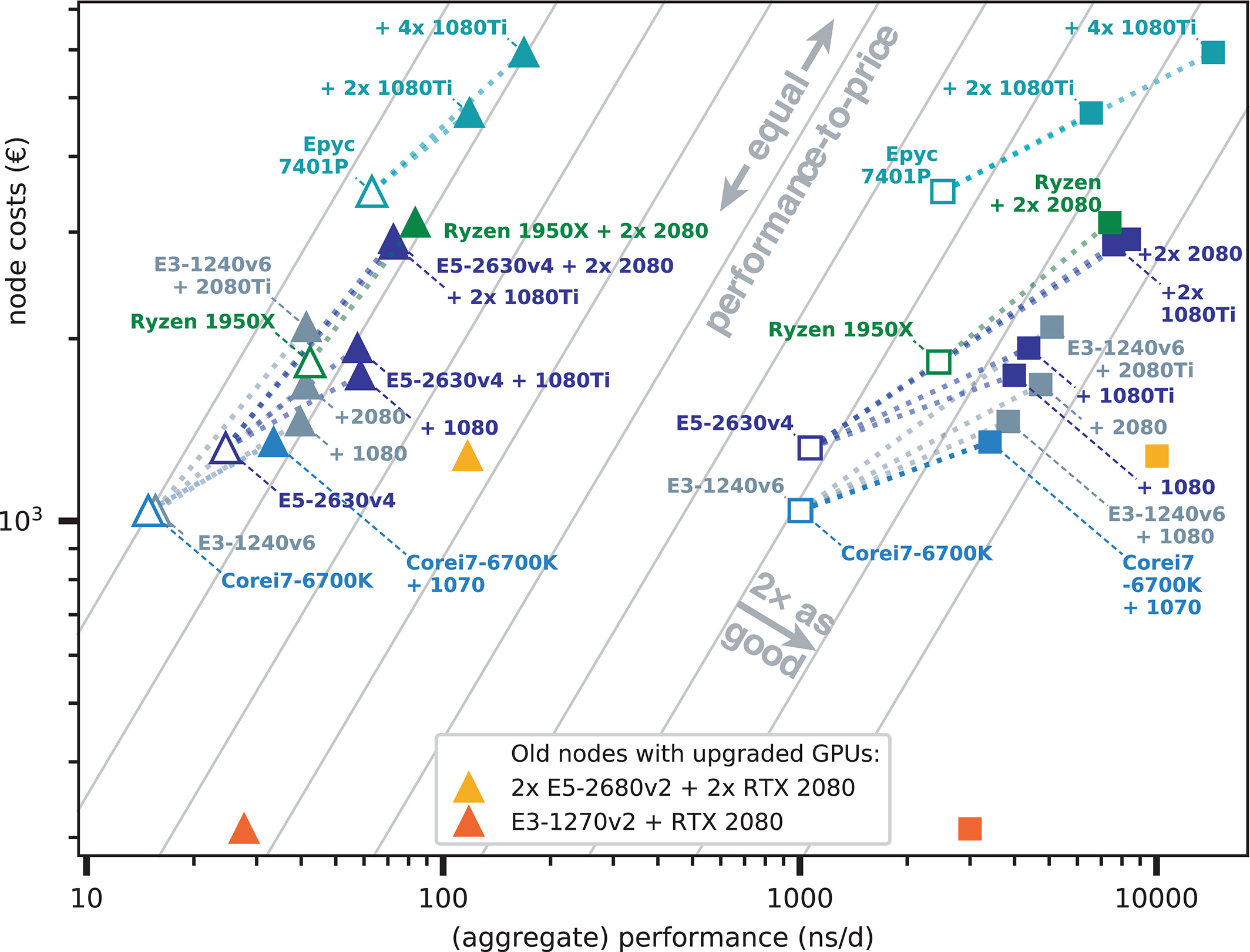
图13: (整体)模拟性能与节点净成本的关系, 类似图9但基于两个Martini力场粗粒化基准测试(囊泡和膜)的结果. VES(正方形)和BIG(三角形)符号的颜色表示CPU类型. 白色填充符号表示无GPU加速的节点; 虚线将GPU节点与对应的CPU连接起来. 使用新GPU的旧节点以橙色(图例)表示.
类似全原子系统, 具有消费级GPU节点的性价比明显高于CPU节点. 然而, CPU节点和消费级GPU节点之间的差距没有全原子情况下的那么明显. 对于小的VES体系, 性价比倍数大约为2-4, 对于BIG膜, 倍数为1.5-2. 与全原子情形一样, 使用最新消费级GPU升级的旧节点具有最好的性价比.
虽然Martini粗粒化MD体系的工作量与全原子系统的工作量(粒子密度较低, 无PME网格)有很大不同, 但事实证明, 对于全原子MD而言最佳的节点型号同样非常适合用于运行粗粒化模拟.
对GROMACS 2018的结论
在2014年, 我们发现, 与无GPU的节点或具有专业GPU的节点相比, 具有消费级GPU的节点提供了效果最佳, 因为它们每欧元所产生的轨迹量显著更高. 对当前硬件, GROMACS 2018也具有相同的结论. 此外, 现有差距已经明显增大: 考虑到节点的原始价格, 现在使用GROMACS 2018, 消费级GPU节点所产生的轨迹可以增加至三到六倍, 相比之下, 2014年使用GROMACS 4.6可以增加至两到三倍. 如果包括能源和冷却成本, 这个倍数从2增加到大约3.
除短距离非键相互作用之外, 这种显著的性能改进可能是因为将PME网格计算卸载到了GPU上. PME卸载使得最佳硬件平衡更倾向于消费级GPU. 通过性价比确定的最佳CPU/GPU组合, 每个1080Ti或2080 GPU大约需要4到8个CPU核心; 一个有用的一般性经验规则是, 对于类似本文所示的模拟体系, 10-15 “core-GHz”就足够了, 而升级到15-20 “core-GHz”(或者具有额外CPU计算能力)的机器在将来也是可以的.
此外, PME卸载为特定于旧GROMACS版本的GPU节点提供了廉价升级的可能性. 将旧的GPU替换为目前最先进的型号, 而其他设备保持不变, GROMACS 2018就可以达到最佳CPU/GPU平衡, 这样对GPU的投资相对较小.
展望
因为硬件在不断发展, 将来可以使用新的组件(CPU, GPU, 裸机, 主板等), 很可能将来会出现比本文所确定的性价比更高的配置. 如果你在使用那些本文未提及的硬件配置, 我们希望你能从https://www.mpibpc.mpg.de/grubmueller/bench下载我们的基准测试输入文件, 这些文件采用CC许可协议, 你可以使用它们进行自己的基准测试, 这样我们在更新表格时可以包含你的数据.
值得指出的是, 本文给出的结果确实适用于GROMACS 2019版, 在撰写本文时它的代码刚刚发布. 在性能方面, 这个新版本只有适度的提高, 但也有一些值得注意的地方. 新版本可以使用OpenCL支持PME卸载, 这在AMD GPU上特别有用, 特别是考虑到(现在已经是上一代的)Radeon Vega GPU相对于其竞争者的优势. 当将它们的性价比与Tesla GPU进行比较时, 它们的优势尤为明显(见图3和4).
2019版本的另一个值得注意的附加功能是, 可以使用CUDA卸载(大多数)成键相互作用. 但是, 由于GROMACS具有针对成键相互作用高度优化的SIMD内核, 因此只有在可用CPU资源较低或模拟系统中包含大量成键相互作用的情况下, 成键卸载功能才会提升性能. 对于我们的基准测试, 这意味着对于只需几个核心与快速GPU配对的情况性能会得到改善, 如图8中紫色和深绿色线在1-3核心范围内所示.
